2.8 效率
选择如何表示和处理数据时,常要权衡效率。效率指计算所用的资源,例如求函数结果或表示对象所需的时间与内存,这些数量会因实现细节而差异巨大。
2.8.1 测量效率
精确测量运行时间或内存很难,因为结果取决于机器配置等诸多细节。更可靠的方式是统计某些事件发生的次数,例如函数调用次数。
回到第一个树递归函数 fib。
>>> def fib(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fib(n - 2) + fib(n - 1)
>>> fib(5)
5计算 fib(6) 的模式如图:为求 fib(5) 需要 fib(3) 与 fib(4),求 fib(3) 又需 fib(1) 与 fib(2)。整体演化像一棵树,遍历时每个蓝点表示某个斐波那契数完成计算。
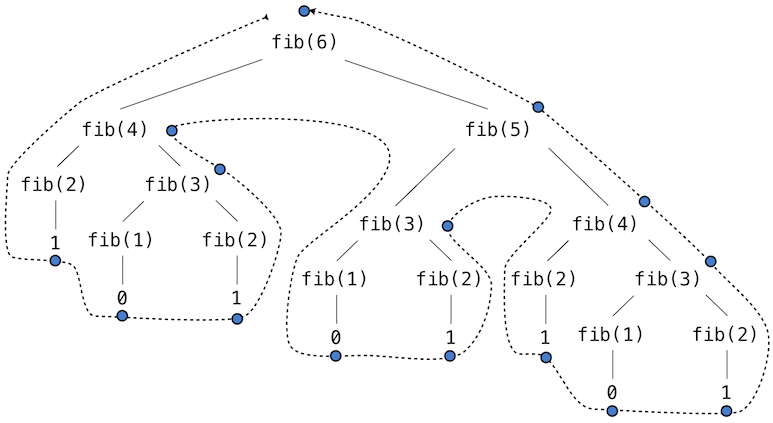
它很有教学意义,但计算斐波那契数极其低效,存在大量冗余:fib(3) 的整个过程会被重复。
我们可以测量这种低效。高阶函数 count 返回与参数等效的函数,并维护 call_count 属性,用以统计调用次数。
>>> def count(f):
def counted(n):
counted.call_count += 1
return f(n)
counted.call_count = 0
return counted统计调用次数可见其增长比斐波那契数列本身还快,这是树递归的典型特征。
>>> fib = count(fib)
>>> fib(19)
4181
>>> fib.call_count
10946空间。要了解函数的空间需求,需要说明环境模型如何使用、保留和回收内存。计算表达式时,解释器保存所有活动环境及其引用的值和帧。环境为某个表达式提供求值上下文即为活动;当创建其首帧的调用返回时,环境变为非活动。
例如计算 fib 时,解释器按树结构顺序计算各值。它只需跟踪当前节点之上的节点,其他分支所用内存可回收,因为不再影响未来计算。树递归所需空间与树的最大深度成正比。
以下的图表描述了计算 fib(3) 时所创建的环境。在计算初始应用 fib 的返回表达式时,表达式 fib(n-2) 被计算,得到一个值为 0。一旦这个值被计算出来,相应的环境帧(被标记为灰色)就不再需要:它不是一个活动环境的一部分。因此,一个良好设计的解释器可以回收用于存储该帧的内存。另一方面,如果解释器当前正在计算 fib(n-1) ,则通过这个 fib 应用(其中 n 为 2)所创建的环境是活动的。反过来,最初用于将 fib 应用于 3 的环境是活动的,因为其返回值尚未被计算出来。
高阶函数 count_frames 用于跟踪未返回的调用次数 open_count,记录计算过程中活动调用数。max_count 是 open_count 曾达到的最大值,对应同时活动的最大帧数。
>>> def count_frames(f):
def counted(n):
counted.open_count += 1
counted.max_count = max(counted.max_count, counted.open_count)
result = f(n)
counted.open_count -= 1
return result
counted.open_count = 0
counted.max_count = 0
return counted
>>> fib = count_frames(fib)
>>> fib(19)
4181
>>> fib.open_count
0
>>> fib.max_count
19
>>> fib(24)
46368
>>> fib.max_count
24总结:fib 的空间需求(按活动帧数)比输入小 1,通常较小;而按递归调用次数衡量的时间需求比输出大,通常巨大。
2.8.2 记忆化
树递归通常可用**记忆化(memoization)**提效:函数会保存已见参数的返回值,第二次调用如 fib(25) 就直接返回缓存。
记忆化可自然写成高阶函数或装饰器。下面创建缓存(cache)存储已计算结果,索引为参数;用字典做缓存要求参数不可变。
>>> def memo(f):
cache = {}
def memorized(n):
if n not in cache:
cache[n] = f(n)
return cache[n]
return memorized如果我们将 memo 应用于斐波那契数列的递归计算,将会产生一个新的计算模式,如下所示。
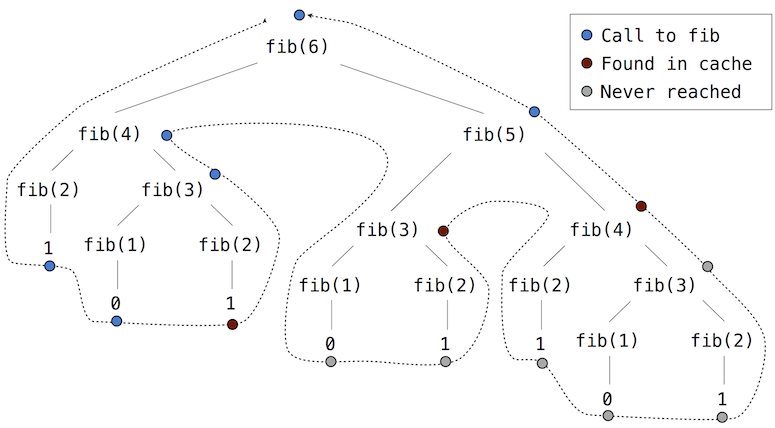
在计算 fib(5) 时,在计算右侧分支的 fib(4) 时,已经计算过的 fib(2) 和 fib(3) 的结果被重复使用。因此,许多树递归计算根本不需要进行。
通过使用 count 函数,我们可以看到对于每个唯一的输入,fib 函数实际上只被调用一次。
>>> counted_fib = count(fib)
>>> fib =memo(count_fib)
>>> fib(19)
4181
>>> counted_fib.call_count
20
>>> fib(34)
5702887
>>> counted_fib.call_count
352.8.3 增长阶数
计算过程消耗资源的速率差异巨大,前面的例子已显示这一点。准确估计调用使用的空间或时间很难,取决于诸多因素。一个有用的分析方法是按需求相似的过程分类,常用分类是增长阶(orders of growth),用简单术语描述资源需求随输入的增长。
为介绍增长阶,分析函数 count_factors:它计算能整除输入
计算 count_factors 需要多少时间?精确答案因机器而异,但可以做一些普遍观察:while 执行次数是小于等于 while 前后的语句各执行一次。总执行语句数约为 是循环体语句数,v` 是循环外语句数。虽然不精确,但足以描述时间随输入的函数关系。
更精确的描述很难。count_factors 的增长阶表明其时间以
Theta 符号(Theta notation) 用于表示算法的渐进性能。设参数
若存在与
则称
- 下界
- 上界
检查函数体可用此定义展示 count_factors(n) 的步骤数量以
下界:取 count_factors(n) 至少需 while 外至少执行 4 行,每行至少 1 步;while 体内至少 2 行,加上 while 头,每次至少 1 步;循环体至少执行
上界:假设函数体任一行至多需 count_factors(n) 最多需 while 外 5 行,循环内 4 行(含 while 头),即便每个 if 都为真,上界仍成立。取
2.8.4 示例:指数运算
考虑计算给定数的指数问题。我们希望有一个函数,它以底数
这个递归定义可以很容易的转化为递归函数:
>>> def exp(b, n):
if n == 0:
return 1
return b * exp(b, n - 1)这是一个线性递归过程,它需要
这意味着递归的指数计算是一个线性过程,它的时间和空间复杂度都随着指数
>>> def exp_iter(b, n):
result = 1
for _ in range(n):
result = result * b
return result我们可以通过使用连续平方法来以更少的步骤计算指数。例如,计算 b 的 8 次幂可以如下进行:
而我们可以使用三次乘法来计算它:
这种方法对于指数是 2 的幂次的情况非常有效。我们也可以利用连续平方法来计算一般情况下的指数,如果我们使用如下递归规则:
我们也可以用一个递归函数的方式来表达这个方法:
>>> def square(x):
return x * x
>>> def fast_exp(b, n):
if n == 0:
return 1
if n % 2 == 0:
return square(fast_exp(b, n // 2))
else:
return b * fast_exp(b, n - 1)
>>> fast_exp(2, 100)
1267650600228229401496703205376通过快速指数运算(fast_exp),计算过程在时间和空间上都以对数级别随 fast_exp 计算
当 fast_exp 只需要 14 次乘法,而不是 1000 次。这显示了使用快速指数运算相对于普通指数运算在效率上的巨大优势。
2.8.5 增长类别
增长阶是为了简化计算过程的分析和比较而设计的。许多不同的计算过程可以具有等效的增长阶,这表示它们的增长方式相似。对于计算机科学家来说,了解和识别常见的增长阶并确定具有相同增长阶的过程是一项重要的技能。
常数项:常数项不影响计算过程的增长阶。因此,例如,
对数:对数的底数不影响计算过程的增长阶。例如,
嵌套:当内部的计算过程在外部过程的每一步中重复执行时,整个过程的增长阶是外部和内部过程的步骤数的乘积。
例如,下面的函数 overlap 计算列表 a 中与列表 b 中出现的元素数量。
>>> def overlap(a, b):
count = 0
for item in a:
if item in b:
count += 1
return count
>>> overlap([1, 3, 2, 2, 5, 1], [5, 4 ,2])
3对于列表的 in 运算符,其时间复杂度为 b 的长度。它被应用 a 的长度。表达式 item in b 是内部过程,而 for item in a 循环是外部过程。该函数的总增长阶是
低阶项。随着计算过程的输入增长,计算中增长最快的部分将主导总的资源使用。
例如,考虑函数 one_more,它返回列表 a 中有多少个元素是另一个元素的值加 1。也就是说,在列表 [3, 14, 15, 9] 中,元素 15 比 14 大 1,所以 one_more 将返回 1。
>>> def one_more(a):
return overlap(a, [x + 1 for x in a])
>>> one_more([3, 14, 15, 9])
1这个计算分为两个部分:列表推导和对 overlap 的调用。对于长度为 overlap 的调用需要
常见的类别。 通过这些等价性,我们可以得到一小组常见的类别来描述大多数计算过程。最常见的类别如下,按从最慢到最快的增长顺序列出,并描述了随着输入增加而增长的情况。接下来将给出每个类别的例子。
| 类别 | 增长阶描述 | 例子 | |
|---|---|---|---|
| 常数 | 增长与输入无关 | abs | |
| 对数 | 增长与输入的大小成正比 | fast_exp | |
| 线性 | 随着输入的递增,计算过程所需的资源会增加 n 个单位 | exp | |
| 乘方 | 随着输入的递增,计算过程所需的资源会增加 n 个单位 | one_more | |
| 指数 | 随着输入的递增,计算过程所需的资源会成倍增加 | fib |
除了这些之外,还有其他的增长阶类别,例如 count_factors 的
指数增长描述了许多不同的增长阶,因为改变底数 fib 的步数随输入
的整数,其中
我们还提到步数与结果值成正比,所以树递归过程需要